Search, don't sort
If I recall correctly, it was Google that first started hammering us with the catchy mantra, "Search, don't sort". I also recall that I wasn't buying the idea. To me, it seemed less like a revolutionary new paradigm, and more like just shifting some of the leg work around. A friend of mine was more enthusiastic. "Wouldn't it be great," he suggested, "if I could store all my images in one place, and instead of having to sort into directories, I could just search for images of 'Paul Hoadley'?" Well, sure, that would be great, except it hides a few implementation details. And the most critical of these is: How does the machine know that a certain image depicts 'Paul Hoadley'? Well, the obvious answer is that my friend would associate some metadata with the image somehow, containing some fragment of information like "depicts: Paul Hoadley". (The details aren't important.) At this point, "search" is starting to look suspiciously close to "sort". In fact, I would argue that they are essentially equivalent, with the only significant difference being how you associate the metadata with the files. In the "sort" scenario, the metadata is implied by, say, the directory structure (or the bookmark structure, or whatever you like—again, the details are not that important). In the "search" scenario, you make the metadata explicit by, say, embedding it in the file, or putting it nearby somewhere.
Of course, images are probably the pathological case (as my friend pointed out), in that there's very little (if any) intrinsic metadata available. That is, you really do have to provide it all yourself. Plain text (such as an email message), on the other hand, is a lot easier to extract useful information from. Hence the appeal of Gmail—you would have to admit that Google seems to have pretty much nailed the plain text searching issue.
All of this is a rather lengthy introduction to something I observed this afternoon. When I heard that Apple (and Microsoft, of course—they never want to be left out) were looking at approaching filesystems in the same way ("search, don't sort"), I was skeptical. It seemed like the kind of thing that could easily be done quite badly. Enter Spotlight. You can read the press release copy and comprehensive reviews elsewhere, but let me just recount what happened to me today.
I have been updating my address book. (I will cover my various iSync experiences in a separate post.) A neat feature of the OS X Address Book is that you can add fields like "partner" and "child" to an entry. I plan to never forget a friend's child's name again. Anyway, I was updating a particular entry, and I had forgotten my friend's partner's last name. But I knew his first name was "Andres", and I was pretty sure I had an email somewhere with his last name in it.
I brought up my Mail window, and, thinking "not a chance", I typed the name into the Spotlight text field.
There were two reasons why I was thinking "not a chance". The first was that I am reading my mail over IMAP from my FreeBSD gateway. That is, the messages are all sitting on that machine, I don't download them to the PowerBook. Despite this, I got two hits straight away:
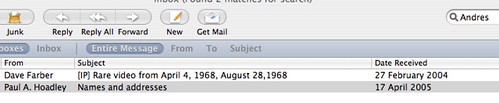
The second hit was the email I was thinking of. The second reason for my skepticism was that the name I was searching for was not in the body of the mail, but in a (plain text) attachment to the mail.
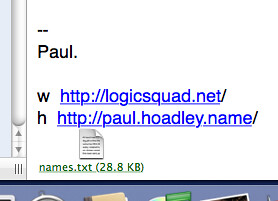
Despite this, Spotlight came up with the goods:

I'm impressed. I think I am going to head back to that Ars Technica review to see how this all works.
Of course, images are probably the pathological case (as my friend pointed out), in that there's very little (if any) intrinsic metadata available. That is, you really do have to provide it all yourself. Plain text (such as an email message), on the other hand, is a lot easier to extract useful information from. Hence the appeal of Gmail—you would have to admit that Google seems to have pretty much nailed the plain text searching issue.
All of this is a rather lengthy introduction to something I observed this afternoon. When I heard that Apple (and Microsoft, of course—they never want to be left out) were looking at approaching filesystems in the same way ("search, don't sort"), I was skeptical. It seemed like the kind of thing that could easily be done quite badly. Enter Spotlight. You can read the press release copy and comprehensive reviews elsewhere, but let me just recount what happened to me today.
I have been updating my address book. (I will cover my various iSync experiences in a separate post.) A neat feature of the OS X Address Book is that you can add fields like "partner" and "child" to an entry. I plan to never forget a friend's child's name again. Anyway, I was updating a particular entry, and I had forgotten my friend's partner's last name. But I knew his first name was "Andres", and I was pretty sure I had an email somewhere with his last name in it.
I brought up my Mail window, and, thinking "not a chance", I typed the name into the Spotlight text field.
There were two reasons why I was thinking "not a chance". The first was that I am reading my mail over IMAP from my FreeBSD gateway. That is, the messages are all sitting on that machine, I don't download them to the PowerBook. Despite this, I got two hits straight away:
The second hit was the email I was thinking of. The second reason for my skepticism was that the name I was searching for was not in the body of the mail, but in a (plain text) attachment to the mail.
Despite this, Spotlight came up with the goods:
I'm impressed. I think I am going to head back to that Ars Technica review to see how this all works.

Comments
Post a Comment